研究方法可以数字化吗?扎根理论的数字化操作指南
记录笔者对于质性研究方法与自然语言处理、知识图谱在文本处理方面相似性的一些发现。
若有观点不一致之处,欢迎探讨!

0 序言
扎根理论的贡献在于从资料中建构理论,在瀚如烟海的数据中寻找观点。机器学习的目的是从数据中发掘价值,通过大量的数据训练、产生模型。从这个角度来看,二者有一定共性,都是从数据开始,经黑箱,得到一个可以用于预测的结果。那么,倘若扎根理论可以借用机器学习的方法对数据进行处理,是否会大大提高编码效率,又是否可以通过增大数据量,大大提高模型的准确度?
笔者经过近期的学习,并与几位老师反复探讨,认为扎根理论的部分环节是可以被数字化的。扎根理论作为一种强调研究者抽象思考的理论建构方法,在现阶段机器学习算法水平的限制下,编码的环节可以被自然语言处理的技术替代;但强调研究者思考的环节(比如属性和维度分析、关联类属等)尚不能被知识图谱的技术替代。
1 扎根理论是什么
管理学领域的研究主要可以分为量化研究和质性研究。质性研究一般由一个宽泛的问题开始,通常没有预先确定的概念。概念是在资料中寻找并建构起来的(科宾,2015,p23)。扎根理论是质性研究的一种研究策略。
质性研究是以研究者本人作为研究工具,在自然情境下采用多种资料收集方法,对社会现象进行整体性研究,主要使用归纳法分析资料和形成理论,通过与研究对象互动,对其行为和意义建构获得解释性理解的一种活动(陈向明,2000)。
1.1 如何运用扎根理论对资料进行分析
首先回顾问题,对资料进行一个整体性的提问:这个资料是一个关于什么的研究?
接着,进行三级编码。
A.一级编码(开放式登录)
开放式登录的过程类似一个漏斗,最开始登录的范围比较宽,随后不断缩小范围。
- 贴标签。对资料内容进行逐行登录,给每个码号一个初步的命名。命名可以使用当事人的原话,也可以使用研究者自己的语言。相似的现象要用同样的码号。这一步实质上是对访谈文本做语义上的分类。
- 类属化。对已有的标签做一次降维,将同类码号提出一个更为抽象的概念。
- 属性和维度分析。发展和丰富类属的内涵,形成类属-属性-维度关系。需要注意的是,要尽量减少一个类属中的属性个数m和维度个数n。
B.二级编码(核心式登录)
在一级编码抽取得到的所有类属中,选择最主要的作为核心类属,将分析集中到与这个核心类属相关的码号上。
- 写故事。在一级编码的基础上进行叙述,形成一个故事。
- 形成故事线。使用故事线将所有编码串起。
- 找到核心类属。对各类属进行描述,填充需要补充的类属,挑选核心类属,比较得出核心类属与其他类属之间系统的联系。
C.三级编码(关联式登录/轴心登录)
发现建立类属之间的各种联系。这个联系可以是因果关系、时间先后关系、语义关系、情境关系、相似关系、差异关系、对等关系、类型关系、结构关系、功能关系、策略关系、过程关系。
在这一步中,研究者每一次只对一个类属进行深度分析,围绕这一个类属寻找相关关系,因此称之为“轴心”。
关联类属的方法:范式模型
按照事件流程,范式模型包括了A因果条件→B现象→C情境条件→D干预条件→E行动/互动策略→F结果,这6个部分代表了一个完整的事件流程(从开始到结果)。
因果条件:致使某一现象产生或发展的事件、事故、事情
现象:具有中心地位的观念、事件、事故、事情
情境条件:从属于某一现象的特定属性,即某现象的属性和维度
干预条件(中介条件):某一现象行动时激活的,具有促进/限制功能的功能。
行动/互助策略:针对某一现象在其可见、特殊的一组条件之下,采取的管理、处置、实施策略。
结果:行动/互助产生的结果。
范式模型选择B现象作为分析抓手,B现象就是二级编码中的核心类属。那么其他5个部分从哪里出?
C情境条件是基于B现象的属性和维度构建。其余4个部分来自二级编码的其余类属。因此二级编码中至少要有5个类属。如果不够,需要返回原文重新编码;如果超过,需要筛选或是合并。
2 知识图谱与自然语言处理
自然语言处理是研究如何利用计算机技术对语言文本进行处理和加工的一门学科。
知识图谱是是对实体(真实世界中的物体、时间或者一些抽象的概念)及其之间相关关系的描述的集合。
知识图谱通过图的方式建构真实世界,点是实体/概念,边是属性/关系。这个图是通过自然语言抽取出来的。
知识图谱的构建步骤:文本处理、实体识别、关系抽取、构建图谱。
(此部分内容由lty师哥整理完成。)
句子分割(Sentence Segmentation)
构建知识图的第一步是将文本文档或文章分解成句子,每句话可以再拆分出主语和宾语。当面对海量数据,我们难以实现句子的人工抽取,需要使用实体识别和关系抽取技术。
实体识别(Entities Recognition)
实体识别就是抽取实体,通过词性标签和提取规则抽取实体,实体将作为知识图谱上的“节点”。
关系抽取(Extract Relations)
关系抽取就是提取实体之间的关系,关系将作为知识图谱上的“边”。一般情况下,将句子中的动词提取为实体间的关系。
构建图谱
导入相关库(Import Libraries)
读取文本数据(Read Data)
抽取"主语-宾语"对(Entity Pairs Extraction)
关系抽取(Relation Extraction)
构建知识图谱(Build a Knowledge Graph)
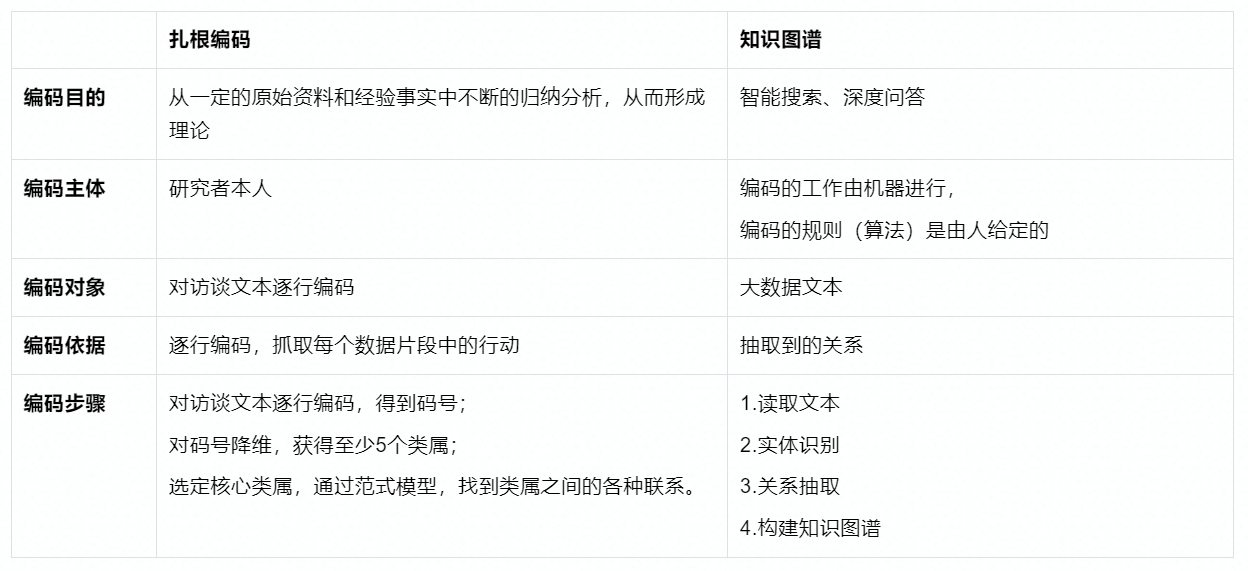
3 扎根编码与知识图谱的相似性
从下表可知,二者思路一致,在操作上有些许区别。
4 如何实现扎根理论的数字化
至此,笔者认为,扎根理论的材料分析部分就是自然语言处理(NLP)。具体而言,一级编码的贴标签、类属化工作可以通过自然语言处理的技术实现。
现有程度:信息化
目前已有辅助扎根编码的软件:Nvivo。但此软件并没有实现真正的自动编码,只是将过去贴便利贴、手动记录的工作信息化了。
难点
1、自然语言处理的数据库多为英文的,尚没有成熟的中文语料库可供使用。
2、缺少成熟的识别实体和抽取关系的算法,需要自行训练。
3、语料库的构建和算法的修正工作,需要大量的专业知识。
5 参考资料
[1]《建构扎根理论:质性研究实践指南》Kathy Charmaz
[2]《质的研究方法与社会科学研究》陈向明
[3]《怎样做好一项研究——小规模社会研究指南》Martyn Denscombe
[4]《质性研究:反思与评论》陈向明
[5] 知识图谱
[6] Neo4J操作指南
图片@小武拉莫